
Section 6 Other Considerations in the Regression Model
When we fit a linear regression model, many problems can occur, to name a few:
- Non-linearity of the response-predictor relationships.
- Correlation of error terms.
- Non-constant variance of error terms.
- Outliner.
- High-leverage points.
- Collinearity.
6.1 Non-linearity of the Data
The first assumption of Linear Regression is that relations between the independent and dependent variables must be linear.
Although this assumption is not always cited in the literature, it is logical and important to check for it. After all, if your relationships are not linear, you should not use a linear model, but rather a non-linear model of which plenty exist.
We can check for linear relationships easily by making a scatter plot for each independent variable with the dependent variable as in Figure 6.1.
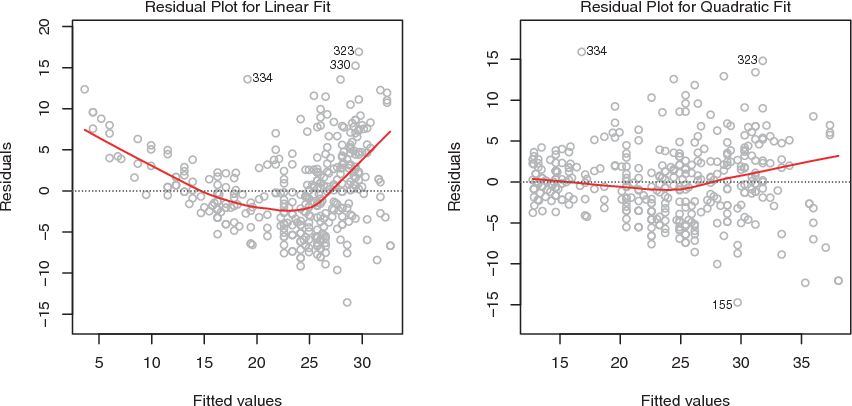
Figure 6.1: Plots of residuals versus predicted (or fitted) values for the Auto data set
In each plot, the red line is a smooth fit to the residuals, intended to make it easier to identify a trend.
- Left: A linear regression of
mpgon horsepower. A strong pattern in the residuals indicates non-linearity in the data. - Right: A linear regression of
mpgonhorsepowerandhorsepower2. There is little pattern in the residuals.
6.2 Correlation of Error Terms
If there is correlation among the error terms \(\epsilon_1, \epsilon_2,...,\epsilon_n\), then the estimated standard errors (SE) will tend to underestimate the true SE. As the result, p-value associated with the model will be lower than they should be, which could cause us to erroneously conclude that a parameter is statistically significant.
Such correlations frequently occur in the context of time series data, which consist of observations for which measurements are obtained at adjacent time points will have positively correlated errors.
In order to determine if this is the case for a given data set, we can plot the residuals from our model as a function of time.
Figure 6.2 provides an illustration. In the top panel, we see the residuals from a linear regression fit to data generated with uncorrelated errors. There is no evidence of a time-related trend in the residuals.
In contrast, the residuals in the bottom panel are from a data set in which adjacent errors had a correlation of 0.9. Now there is a clear pattern in the residuals—adjacent residuals tend to take on similar values.
Finally, the center panel illustrates a more moderate case in which the residuals had a correlation of 0.5. There is still evidence of tracking, but the pattern is less clear.
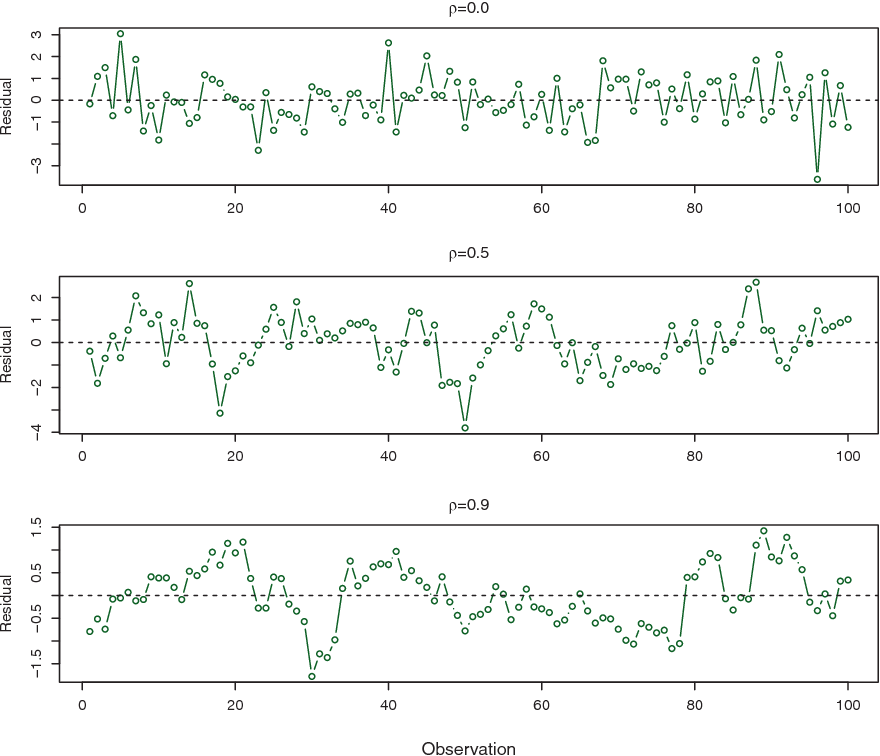
Figure 6.2: Plots of residuals from simulated time series data sets generated with differing levels of correlation p between error terms for adjacent time
6.3 Non-constant Variance of Error Terms (Heteroscedasticity)
Heteroscedasticity in a model means that the error is constant along the values of the dependent variable.
One can identify non-constant variances in the errors, or heteroscedasticity, from the presence of a funnel shape in heteroscedathe residual plot.
An example is shown in the left-hand panel of Figure 6.3, heteroscedasticity in which the magnitude of the residuals tends to increase with the fitted values. In each plot, the red line is a smooth fit to the residuals, intended to make it easier to identify a trend. The blue lines track the outer quantiles of the residuals, and emphasize patterns:
Left: The funnel shape indicates heteroscedasticity.
Right: The response has been log transformed, and there is now no evidence of heteroscedasticity.
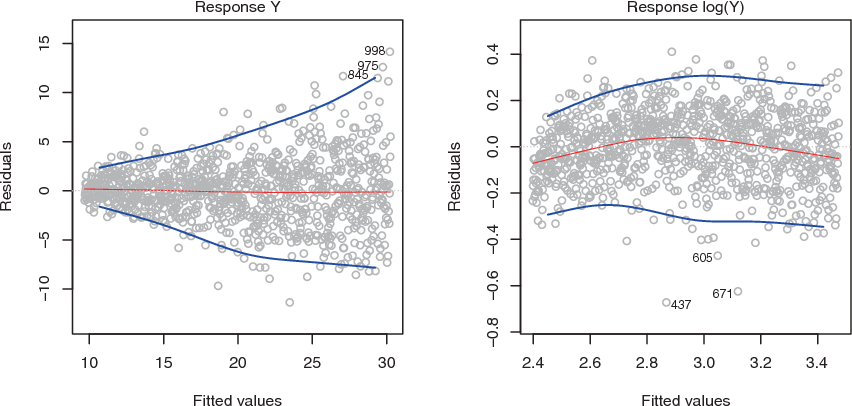
Figure 6.3: Residual plots
Some of the suggested solutions are:
Do some work on your input data like having some variables to add or remove.
Do transformations, like applying concave function such as logistics (\(logY\)) or square root \(\sqrt{Y}\).
If this doesn’t change anything, you can also switch to the weighted least squares model. Weighted least squares is a model that can deal with unconstant variances and heteroscedasticity is therefore not a problem.
6.4 Outlier
An outlier is a point for which \(y_i\) is far from the value predicted by model. Outliers can arise for a variety of reasons, such as incorrect recording of an observation during data collection.
As illustrated in Figure 6.4:
Left: The least squares regression line is shown in red, and the regression line after removing the outlier is shown in blue.
Center: The residual plot clearly identifies the outlier.
Right: The outlier has a studentized residual of 6; typically we expect values between −3 and 3.
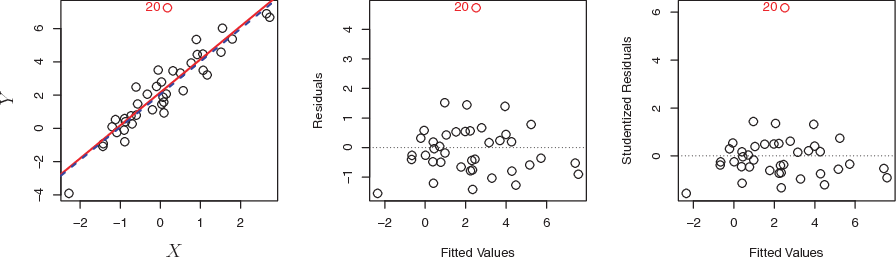
Figure 6.4: Outlier plots
If we believe that an outlier has occurred due to an error in data collection or recording, then one solution is to simply remove the observation.
6.5 High Leverage Points
In contrast to outlier with unusual for response value \(y\), observations with high leverage have an unusual value for \(x_i\).
As illustrated in Figure 6.5:
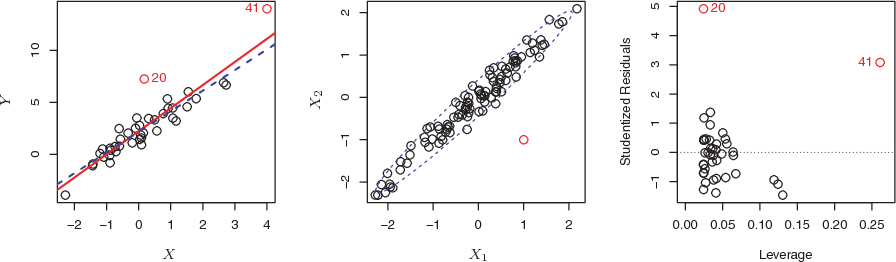
Figure 6.5: Leveraging Observations Plots
Left: Observation 41 is a high leverage point, while 20 is not. The red line is the fit to all the data, and the blue line is the fit with observation 41 removed.
Center: The red observation is not unusual in terms of its X1 value or its X2 value, but still falls outside the bulk of the data, and hence has high leverage.
Right: Observation 41 has a high leverage and a high residual.
In order to quantify an observation’s leverage, we compute the leverage statistic as in (6.1):
\[\begin{equation} \Large h_i = \frac{1}{n} + \frac{(x_i - \overline{x})^2}{\sum_{i'=1}^{n}(x_i' - \overline x)^2} \tag{6.1} \end{equation}\]
A large value of this statistic indicates an observation with high leverage.
6.6 Collinearity
Collinearity refers to the situation in which two or more predictor variables are closely related to one another.
In order to check for collinearity, we can either use Correlation Matrix or Variance Inflation Factor (VIF).
6.6.1 Correlation Matrix
A simple way to detect collinearity is to look at the correlation matrix of the predictors. An element of this matrix that is large in absolute value indicates a pair of highly correlated variables, and therefore a collinearity problem in the data.
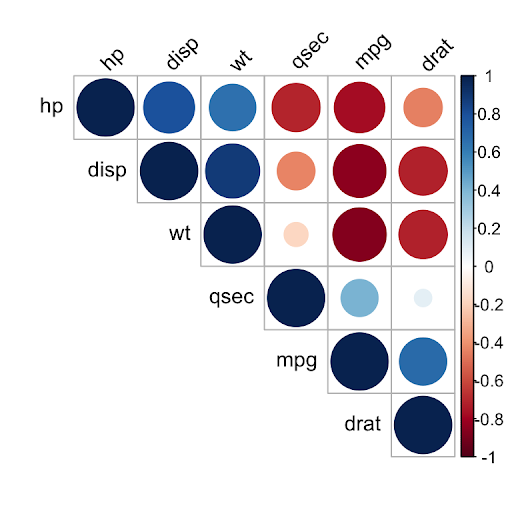
Figure 6.6: Sample Correlation Matrix using R
Unfortunately, not all collinearity problems can be detected by inspection of the correlation matrix: it is possible for collinearity to exist between three or more variables even if no pair of variables has a particularly high correlation. We call this situation multicollinearity.
Multicollinearity causes problems in using regression models to draw conclusions about the relationships between predictors and outcome. An individual predictor’s p-value may test non-significant even though it is important. Confidence intervals for regression coefficients in a multicollinear model may be so high that tiny changes in individual observations have a large effect on the coefficients, sometimes reversing their signs.
6.6.2 Variance Inflation Factor (VIF)
Instead of inspecting the correlation matrix, a better way to assess collinearity is to compute the variance inflation factor (VIF). This can easily be calculated in R using software packages.
When faced with the problem of collinearity, there are two simple solutions:
The first is to drop one of the problematic variables from the regression.
The second solution is to combine the collinear variables together into a single predictor.